Robots.txt : tout comprendre sur ce fichier indispensable au SEO
Le fichier robots.txt est l’un des éléments techniques les plus puissants et paradoxalement les plus mal compris du référencement naturel. Mal configuré, il peut littéralement faire disparaître votre site de Google du jour au lendemain. Bien optimisé, il devient un véritable accélérateur de visibilité en orientant intelligemment les robots des moteurs de recherche vers vos contenus stratégiques.

Dans ce guide complet, fruit de plus de 15 ans d’expérience terrain sur des projets allant du site vitrine local à la plateforme e-commerce multi-millions de pages, nous allons décortiquer le fichier robots.txt sous tous ses angles : définition, fonctionnement, syntaxe, exemples concrets, erreurs critiques à éviter et bonnes pratiques 2026 pour transformer ce simple fichier texte en levier SEO redoutable.
L’essentiel à retenir
Le fichier robots.txt est un fichier texte placé à la racine de votre site qui donne des instructions aux robots d’exploration (Googlebot, Bingbot, etc.) sur les URL qu’ils peuvent ou ne peuvent pas crawler. Il ne sert pas à désindexer une page pour cela, il faut utiliser la balise noindex. Bien utilisé, il préserve votre budget crawl, protège vos ressources sensibles et améliore l’efficacité de l’indexation de vos pages stratégiques.
Qu’est-ce qu’un fichier robots.txt ? Définition simple
Le fichier robots.txt est un simple fichier au format texte (.txt) placé à la racine d’un site web c’est-à-dire accessible à l’adresse https://votresite.fr/robots.txt. Son rôle est de communiquer avec les robots d’exploration (aussi appelés crawlers, spiders ou bots) des moteurs de recherche pour leur indiquer quelles parties de votre site ils ont le droit d’explorer, et lesquelles leur sont interdites.
Pensez-y comme à un panneau d’accueil placé à l’entrée d’un immeuble : il ne ferme pas les portes à clé, mais il indique poliment aux visiteurs sérieux où ils peuvent aller et où ils ne devraient pas s’aventurer. Les robots respectueux (Googlebot, Bingbot, Yandex…) suivent ces consignes ; les bots malveillants, eux, peuvent tout à fait les ignorer.
Une petite histoire du robots.txt
Le protocole d’exclusion des robots, plus connu sous le nom de Robots Exclusion Protocol (REP), est né en février 1994. À l’époque, un développeur néerlandais nommé Martijn Koster, qui travaillait sur le moteur de recherche WebCrawler, voyait son serveur littéralement écrasé par les crawlers qui visitaient certaines pages en boucle. Pour mettre fin à ce chaos, il proposa une convention simple : un fichier texte à la racine du site dictant la conduite à tenir aux robots.
Restée un standard informel pendant près de 30 ans, cette convention a finalement été officialisée par l’IETF en septembre 2022 sous le RFC 9309, après une proposition portée par Google. Aujourd’hui, le robots.txt est universellement reconnu et respecté par l’ensemble des moteurs de recherche sérieux.
À quoi ressemble concrètement un fichier robots.txt ?
Voici un exemple basique :
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://votresite.fr/sitemap.xml
Trois lignes seulement, mais déjà beaucoup d’informations : on autorise tous les robots à explorer le site, sauf le dossier d’administration (sauf un fichier spécifique nécessaire au bon fonctionnement), et on indique au passage où trouver le sitemap XML.
À quoi sert vraiment le fichier robots.txt ? (et à quoi il ne sert PAS)
C’est ici que beaucoup de propriétaires de sites se trompent. Clarifions une bonne fois pour toutes ce que le robots.txt peut et ne peut pas faire.
Les 5 usages réels du robots.txt
- Préserver le budget crawl de votre site Google alloue à chaque site un quota d’exploration limité, appelé budget crawl. Sur un site de 50 pages, ce n’est pas un problème. Sur un site e-commerce de 100 000 références, chaque URL inutilement explorée est une URL utile qui ne le sera pas. Le robots.txt permet de canaliser les robots vers ce qui compte vraiment.
- Bloquer les pages techniques inutiles Pages de filtres à facettes, paniers, comptes utilisateurs, pages de recherche interne, URL avec paramètres : autant de contenus qui n’ont aucune valeur SEO et qui méritent d’être exclus de l’exploration.
- Protéger les ressources en cours de développement Une zone de préproduction, un dossier de tests, une bêta : autant d’environnements qu’il vaut mieux soustraire au regard de Googlebot.
- Indiquer l’emplacement du sitemap La directive Sitemap: permet de pointer les robots directement vers votre plan de site XML, accélérant ainsi la découverte de vos pages stratégiques. Pour bien comprendre cet aspect, consultez notre guide dédié au sitemap SEO.
- Gérer la fréquence d’exploration Sur certains moteurs (Bing, Yandex), la directive Crawl-delay permet de limiter la cadence des robots pour éviter de surcharger un serveur fragile. À noter : Google ignore cette directive et utilise sa propre logique adaptative.
Ce que le robots.txt NE FAIT PAS (attention, c’est crucial)
Voici l’erreur la plus répandue, et la plus coûteuse en référencement :
Le robots.txt ne désindexe pas une page. Il interdit son exploration, ce qui est très différent.
Concrètement, si une page est déjà indexée par Google, le simple fait de la bloquer dans le robots.txt ne la fera pas disparaître des résultats de recherche. Pire encore : si d’autres sites pointent vers cette URL, Google continuera de l’afficher dans la SERP avec parfois un texte du type « Aucune information n’est disponible pour cette page ».
Pour véritablement empêcher une page d’apparaître dans Google, vous devez :
- Utiliser la balise meta <meta name= »robots » content= »noindex »> directement dans le <head> de la page concernée ;
- Ou utiliser l’en-tête HTTP X-Robots-Tag: noindex ;
- Ou protéger la page par mot de passe ;
- Ou demander sa suppression via la Google Search Console.
Et surtout, autorisez le crawl de la page concernée dans votre robots.txt, sinon Googlebot ne pourra jamais voir la balise noindex que vous y avez placée !
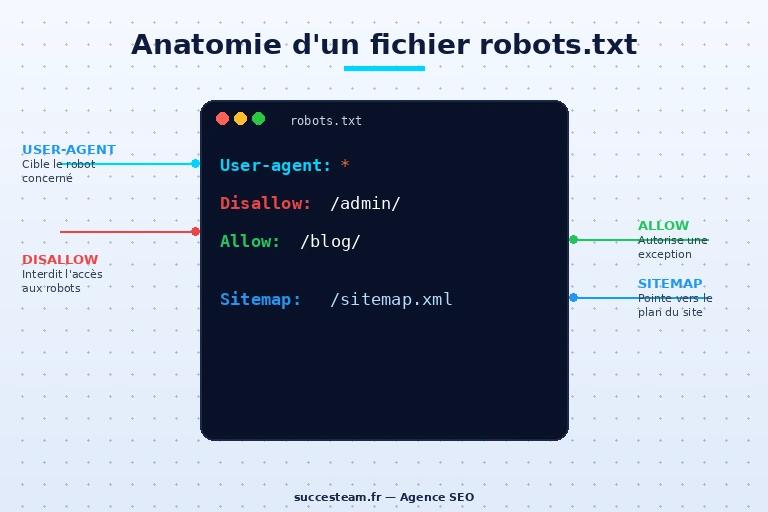
Comment fonctionne le robots.txt ? Anatomie et syntaxe expliquées
Le robots.txt repose sur une syntaxe simple mais rigoureuse. La moindre faute de frappe peut transformer une instruction anodine en catastrophe SEO. Voici les briques essentielles à maîtriser.
Les directives fondamentales
User-agent Cette directive désigne le robot à qui s’adressent les règles qui suivent. L’astérisque * signifie « tous les robots ». On peut aussi cibler un crawler spécifique :
User-agent: Googlebot → Robot principal de Google
User-agent: Googlebot-Image → Robot dédié aux images Google
User-agent: Bingbot → Robot de Bing
User-agent: * → Tous les robots
Disallow Interdit l’accès à une URL, un dossier ou un type de fichier. La règle s’applique à tout ce qui commence par le chemin indiqué.
Disallow: /admin/ → Bloque tout le dossier /admin/
Disallow: /panier → Bloque toute URL commençant par /panier
Disallow: /*? → Bloque les URL avec paramètres (?)
Disallow: /*.pdf$ → Bloque tous les fichiers PDF
Allow Autorise l’accès, généralement utilisée pour faire une exception à une règle Disallow plus large.
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap Indique l’emplacement de votre sitemap XML. On peut en déclarer plusieurs, et cette directive est indépendante du bloc User-agent.
Sitemap: https://votresite.fr/sitemap.xml
Sitemap: https://votresite.fr/sitemap-images.xml
Les caractères spéciaux à connaître
| Symbole | Signification | Exemple |
|---|---|---|
| * | N’importe quelle suite de caractères | Disallow: /*.pdf |
| $ | Fin de l’URL | Disallow: /*.jpg$ |
| # | Commentaire (ignoré par les robots) | # Mon commentaire |
| / | Racine du site | Disallow: / (bloque tout) |
L’ordre de priorité des règles
Google applique une règle simple mais qu’il faut bien comprendre : la directive la plus spécifique l’emporte. Si vous avez :
User-agent: *
Disallow: /blog/
Allow: /blog/article-important/
Alors /blog/article-important/ sera bien exploré, malgré l’interdiction générale sur /blog/. Cette logique de spécificité est précieuse pour créer des règles fines.
7 exemples concrets de fichiers robots.txt prêts à l’emploi
Plutôt que de vous noyer dans la théorie, voici des modèles éprouvés selon le type de site. Adaptez-les à votre cas, jamais l’inverse.
1. Site classique (vitrine, blog) — configuration équilibrée
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /?s=
Allow: /wp-admin/admin-ajax.php
Sitemap: https://votresite.fr/sitemap.xml
2. Site e-commerce — préserver le budget crawl
User-agent: *
Disallow: /panier/
Disallow: /checkout/
Disallow: /mon-compte/
Disallow: /*?orderby=
Disallow: /*?filter_
Disallow: /*?add-to-cart=
Allow: /
Sitemap: https://votresite.fr/sitemap_index.xml
Sitemap: https://votresite.fr/product-sitemap.xml
3. Autoriser tous les robots à explorer tout le site
User-agent: *
Disallow:
(Un Disallow: vide signifie « rien n’est interdit ».)
4. Bloquer complètement un site (préproduction, maintenance)
User-agent: *
Disallow: /
⚠️ Attention : c’est la directive la plus dangereuse du SEO. Oubliée en passant un site en production, elle peut faire disparaître une marque entière de Google.
5. Bloquer un bot spécifique (par exemple un scrapeur agressif)
User-agent: AhrefsBot
Disallow: /
User-agent: *
Disallow:
6. Bloquer les robots IA (tendance 2026)
Avec la montée en puissance des IA génératives, de plus en plus de sites souhaitent contrôler l’usage de leurs contenus par ces modèles :
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
7. Configuration multi-langue avec sitemaps localisés
User-agent: *
Disallow: /admin/
Disallow: /*?lang=
Sitemap: https://votresite.fr/sitemap-fr.xml
Sitemap: https://votresite.fr/sitemap-en.xml
Sitemap: https://votresite.fr/sitemap-es.xml
Comment créer et installer un fichier robots.txt ?
La création du fichier est étonnamment simple. C’est sa stratégie qui demande de la réflexion.
Étape 1 — Créer le fichier
Ouvrez n’importe quel éditeur de texte brut : Bloc-notes (Windows), TextEdit en mode texte (Mac), Notepad++, Sublime Text ou Visual Studio Code. Surtout, pas Word ni Google Docs, qui ajoutent du formatage incompatible.
Tapez vos directives, puis enregistrez le fichier sous le nom exact robots.txt (en minuscules, avec un « s » à robots c’est une faute fréquente d’écrire « robot.txt » au singulier, ce qui rend le fichier totalement inopérant). L’encodage doit impérativement être en UTF-8.
Étape 2 — Placer le fichier à la racine du site
Le fichier doit obligatoirement être déposé à la racine de votre domaine, c’est-à-dire qu’il doit être accessible à https://votresite.fr/robots.txt. S’il est placé dans un sous-dossier (https://votresite.fr/seo/robots.txt), il sera ignoré par les robots.
Sur WordPress, plusieurs solutions existent :
- Via FTP : connectez-vous à votre serveur avec FileZilla, déposez le fichier dans le répertoire racine (souvent public_html ou www).
- Via un plugin SEO : Yoast SEO et Rank Math intègrent un éditeur de robots.txt directement dans leur interface. Pratique, mais attention à ne pas écraser une configuration personnalisée.
- Via votre hébergeur : l’interface cPanel ou Plesk permet aussi de gérer ce fichier facilement.
Étape 3 — Vérifier que le fichier est bien lu par Google
Rendez-vous dans la Google Search Console, dans la rubrique « Paramètres » puis « robots.txt ». Vous y verrez la dernière version récupérée par Google, la date de récupération, ainsi que les éventuelles erreurs de syntaxe détectées. C’est aussi à cet endroit que vous pouvez demander une nouvelle exploration du fichier après une modification.
Étape 4 — Tester ses directives
Avant de mettre en ligne, validez vos règles avec des outils comme :
- Robots.txt Tester (intégré à la Search Console pour les anciens comptes)
- TechnicalSEO.com / robots.txt tester (gratuit en ligne)
- Screaming Frog SEO Spider (qui simule le comportement de Googlebot face à votre fichier)
Les 8 erreurs critiques à ne JAMAIS commettre avec robots.txt
Après avoir audité plusieurs centaines de sites, j’ai vu les mêmes erreurs revenir encore et encore. Voici celles qui ont coûté le plus cher en trafic à mes clients.

- Le fameux Disallow: / oublié en production Le scénario classique : le développeur bloque tout le site en préprod pour éviter qu’il soit indexé. Mise en production… et personne ne pense à modifier le robots.txt. Résultat : tout le site disparaît de Google. Vérifiez toujours votre robots.txt après une mise en ligne.
- Bloquer le CSS et le JavaScript Pendant des années, on a recommandé de bloquer les dossiers /css/ et /js/. C’est terminé. Googlebot a besoin d’accéder à ces ressources pour comprendre comment votre page s’affiche, notamment sur mobile. Bloquer ces fichiers nuit à votre responsive design perçu par Google.
- Croire que robots.txt désindexe On en a déjà parlé, mais ça mérite une seconde mention. Pour désindexer une page déjà connue de Google, utilisez noindex, pas Disallow.
- Une faute d’orthographe sur le nomrobot.txt, Robots.txt, ROBOTS.TXT… seul robots.txt (tout en minuscules, avec « s ») fonctionne. Idem pour les directives : Disalow, Dissallow, disallow: (sans majuscule au D, ça reste accepté, mais soyons rigoureux).
- Mauvais encodage Un fichier robots.txt enregistré en ANSI ou UTF-16 peut ne pas être interprété correctement. UTF-8 obligatoire.
- Oublier de mettre à jour le sitemap Vous changez l’URL de votre sitemap ? N’oubliez pas de mettre à jour la directive Sitemap: du robots.txt en parallèle.
- Bloquer la page de connexion d’un site… qui contient un lien vers le site lui-même Cas tordu mais fréquent : en bloquant /login/, on bloque parfois sans le vouloir des URL essentielles que les robots utilisent pour découvrir d’autres contenus.
- Un fichier trop lourd La limite officielle imposée par Google est de 500 Kio (kibibytes). Tout ce qui dépasse est ignoré. Sauf cas très particuliers (sites énormes avec des milliers de règles), vous resterez largement sous ce seuil.
Robots.txt et SEO : impact réel sur votre référencement
Soyons honnêtes : avoir un fichier robots.txt ne va pas, en soi, faire grimper votre site dans les SERP. Ce n’est pas un critère de positionnement direct. Mais son rôle dans la mécanique d’indexation est tel qu’un robots.txt bien optimisé devient un facteur indirect majeur de performance SEO.
L’impact sur le budget crawl
Sur les gros sites, l’optimisation du budget crawl peut littéralement transformer la visibilité organique. En empêchant Googlebot de gaspiller des ressources sur des pages sans valeur (filtres, paramètres, doublons), vous le concentrez sur vos pages stratégiques. Sur un projet e-commerce de 80 000 références que j’ai accompagné en 2024, une simple refonte du robots.txt a permis d’augmenter de 34 % le nombre de pages indexées utiles en moins de deux mois.
L’impact sur le duplicate content
En bloquant les versions paramétrées de vos URL (filtres, tris, pages de session…), vous limitez naturellement la production de duplicate content, un fléau pour le référencement naturel. Combiné à une bonne gestion des URL canoniques, c’est un duo gagnant pour la santé technique de votre site.
L’impact sur l’indexation des pages prioritaires
En guidant les robots vers les bonnes pages via la directive Sitemap:, vous accélérez la découverte et l’indexation de vos contenus stratégiques. Pour les sites qui publient fréquemment (blogs, médias, e-commerces avec rotations rapides), c’est un avantage compétitif réel pour viser la position 0 sur Google et conquérir la SERP.
Robots.txt et IA génératives : le nouveau front du SEO en 2026
Voici la grande nouveauté de ces dernières années, et la raison pour laquelle le robots.txt connaît une seconde jeunesse. Avec l’explosion des IA génératives (ChatGPT, Claude, Gemini, Perplexity…), les éditeurs de sites se sont retrouvés face à un dilemme : doivent-ils laisser leurs contenus nourrir gratuitement ces modèles ?
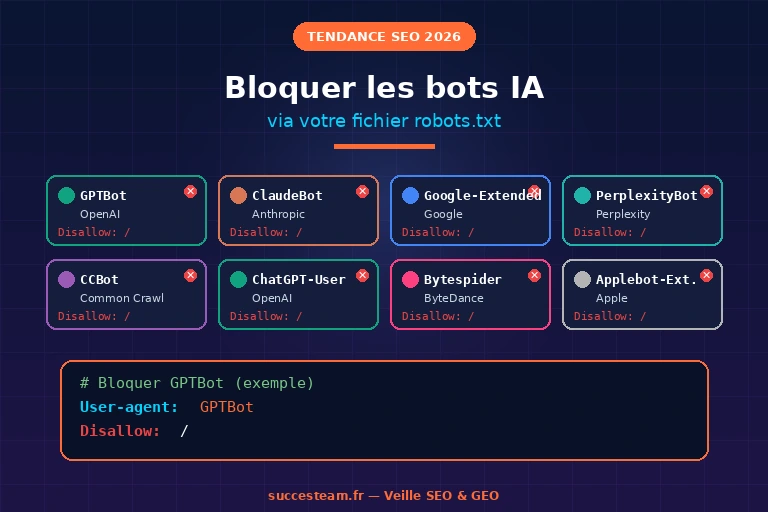
Beaucoup ont fait le choix de bloquer ces robots. Et le robots.txt est l’outil tout désigné pour ça. Voici les User-agents les plus couramment ciblés :
| Robot | À qui il appartient | Usage |
|---|---|---|
| GPTBot | OpenAI | Entraînement de ChatGPT |
| ChatGPT-User | OpenAI | Navigation en temps réel par ChatGPT |
| Google-Extended | Entraînement de Bard / Gemini | |
| ClaudeBot | Anthropic | Entraînement de Claude |
| CCBot | Common Crawl | Dataset public d’entraînement IA |
| PerplexityBot | Perplexity | Moteur de recherche IA |
| Bytespider | ByteDance / TikTok | Entraînement IA |
⚠️ Attention au revers de la médaille : si votre stratégie inclut une présence dans les réponses IA (Generative Engine Optimization, ou GEO), bloquer ces robots vous prive d’opportunités de visibilité dans les outils de demain. Réfléchissez à votre positionnement avant de tout fermer.
Robots.txt, sitemap XML et balise meta robots : qui fait quoi ?
C’est la question piège classique. Ces trois outils sont complémentaires, jamais redondants. Voici la matrice de décision pour ne plus vous tromper.
| Besoin | Outil à utiliser |
|---|---|
| Empêcher l’exploration d’une URL | robots.txt (Disallow) |
| Empêcher l’indexation d’une URL | Balise noindex |
| Indiquer les pages stratégiques à explorer | Sitemap XML |
| Économiser le budget crawl sur de gros sites | robots.txt |
| Désindexer une page déjà indexée | noindex + autoriser le crawl |
| Bloquer une zone privée du site | Mot de passe (htaccess) |
La règle d’or : robots.txt agit sur le crawl, noindex agit sur l’index. Ne confondez jamais les deux.
Confiez votre robots.txt à un expert pour sécuriser votre SEO
Le fichier robots.txt est un outil simple en apparence mais dont chaque ligne peut avoir un impact spectaculaire positif ou catastrophique sur votre référencement naturel. Un mauvais paramétrage peut faire disparaître des milliers de pages des résultats de Google en moins de 48 heures. À l’inverse, un robots.txt parfaitement optimisé concentre la puissance d’exploration des moteurs sur vos pages les plus stratégiques et accélère votre montée dans les SERP.
Chez Succesteam, notre agence SEO audite, conçoit et optimise les fichiers robots.txt de sites de toutes tailles : sites vitrines, blogs, e-commerces, plateformes SaaS. Nous combinons cette expertise technique avec une stratégie globale de référencement naturel, de rédaction web et de création de site internet pour vous garantir une visibilité durable sur Google. Pour faire le point sur votre fichier robots.txt et identifier les optimisations à mettre en place dès aujourd’hui :
Pour aller plus loin dans les définitions et termes clés du SEO, consultez notre glossaire du référencement naturel :