Noindex : le guide complet pour maîtriser l’indexation de vos pages
Le noindex est une instruction adressée aux moteurs de recherche pour leur demander de ne pas afficher une page dans leurs résultats. Concrètement, on l’ajoute via la balise <meta name= »robots » content= »noindex »> dans le <head> de la page (ou via l’en-tête HTTP X-Robots-Tag). La page reste accessible aux visiteurs qui ont le lien, mais elle devient invisible dans Google. C’est un outil de pilotage SEO précieux… à condition de ne pas le confondre avec le robots.txt ou la balise canonical.
Toutes vos pages n’ont pas vocation à apparaître dans Google. Une page panier, un espace client, un résultat de recherche interne, une page de remerciement après formulaire… les afficher dans les résultats n’apporte rien et peut même affecter le PageRank et bruler votre budget crawl.

C’est dans ce cas précis que l’instruction noindex peut être une option envisageable. Dans ce guide, on vous explique simplement ce qu’il est, quelles pages désindexer, comment le mettre en place (les 3 méthodes), et surtout les pièges à éviter y compris celui que la plupart des articles répètent à tort. On finit par l’angle que personne ne traite : le noindex à l’ère de l’IA et du GEO. Suivez le guide ! 😉
Qu’est-ce que le noindex ?
Le noindex est une directive SEO qui demande aux robots des moteurs de recherche de ne pas indexer une page, c’est-à-dire de ne pas l’inclure dans leurs pages de résultats (les SERP). La page existe toujours, elle se charge normalement pour vos visiteurs, mais elle ne « ressort » plus sur Google, Bing ou autres.
Elle se déclare le plus souvent dans la balise meta robots, placée dans la section <head> du code HTML :
<meta name= »robots » content= »noindex »>
On peut la combiner avec une consigne sur les liens de la page :
<meta name= »robots » content= »noindex, follow »>
- noindex → ne pas indexer la page.
- follow → continuer malgré tout à suivre les liens présents sur la page (pour transmettre la découverte des pages liées).
- nofollow → ne pas suivre les liens de la page.
💡 À retenir : indexation ≠ exploration. Le robot doit d’abord explorer (crawler) votre page pour lire la balise noindex. S’il ne peut pas y accéder, il ne verra jamais votre consigne. On y revient plus bas c’est l’erreur n°1.
À quoi sert le noindex ?
Quelques raisons concrètes de désindexer une page :
- Éviter le contenu pauvre : des pages sans réelle valeur (pages de remerciement, tunnels, pages de test) ne devraient pas servir de « porte d’entrée » à un internaute.
- Préserver votre budget de crawl : sur un gros site, vous évitez à Google de gaspiller ses ressources sur des URL sans intérêt, pour qu’il se concentre sur vos pages stratégiques.
- Protéger des pages sensibles ou fonctionnelles : espace client, page de connexion, panier, confirmation de commande… utiles aux utilisateurs, inutiles dans Google.
- Gérer des pages temporaires : une promotion saisonnière ou une landing d’événement passée peut être retirée des résultats sans être supprimée.
⚠️ Cas particulier du duplicate content : on lit souvent « mets tes pages dupliquées en noindex ». C’est rarement le bon réflexe. Pour des doublons (variantes, filtres, versions imprimables), la bonne directive est la balise URL canonique (canonical), qui consolide la valeur SEO vers la page principale. Le noindex, lui, retire la page sans transmettre cette valeur.
Quelles pages mettre en noindex ?
Voici une liste synthétique, valable quel que soit votre CMS, à adapter à votre cas.
Sur un site vitrine ou un blog :
- Pages légales sans valeur SEO : mentions légales, politique de confidentialité, politique de cookies.
- Pages de remerciement (« Merci, votre message a bien été envoyé »).
- Résultats de recherche interne au site.
- Contenus générés automatiquement et pauvres : archives d’auteur, archives par date, archives de formats, étiquettes (tags) non utilisées qui créent souvent du contenu dupliqué.
Sur un site e-commerce, en plus :
- Pages CGV / conditions d’utilisation.
- Page panier, page « Mon compte », page de validation de commande.
- Page wishlist / liste d’envies.
- Certaines facettes et filtres qui génèrent des URL en quasi-double.
Attention aux pages créées « dans votre dos » : de nombreuses extensions (constructeurs de page, gestion de pop-ups, galeries, newsletters…) génèrent des URL indésirables. Un simple audit technique avec un crawler comme Ahrefs révèle souvent des centaines d’URL parasites qu’on ne soupçonnait pas.
Quand NE PAS utiliser le noindex ?
Le noindex mal posé peut littéralement saboter votre référencement naturel. Évitez-le :
- Sur vos pages stratégiques : toute page qui génère du trafic organique, des leads ou des ventes doit rester indexée. Une erreur ici, et la page disparaît de Google.
- Sur une page qui reçoit des backlinks : si vous la désindexez, le « jus SEO » de ces liens entrants est en grande partie perdu. Pensez plutôt à une redirection ou à une consolidation.
- Sur une page de pagination utile : généralement, on laisse la page 1 indexable et on gère le reste finement, sans tout couper.
- Sur une page FAQ riche : une bonne FAQ peut répondre directement à des requêtes ; la désindexer serait dommage.
🧠 Bon à savoir : si une page reste en noindex très longtemps, Google finit par traiter ses liens comme des nofollow. Le noindex n’est donc pas neutre sur le long terme pour le maillage.
Comment mettre une page en noindex ? Les 3 méthodes
1. La balise meta robots (méthode HTML standard)
La plus courante, pour une page HTML. Placez dans le <head> :
<meta name= »robots » content= »noindex »>
Pour ne cibler que Googlebot :
<meta name= »googlebot » content= »noindex »>
2. L’en-tête HTTP X-Robots-Tag (la méthode que tout le monde oublie)
Et pour un PDF, une image, ou un fichier non-HTML ? Vous ne pouvez pas y insérer de balise meta. La solution, c’est l’en-tête de réponse HTTP X-Robots-Tag, envoyé par le serveur. C’est aussi la méthode idéale pour désindexer à grande échelle (par motif d’URL, type de fichier…).
Exemple d’en-tête renvoyé par le serveur :
X-Robots-Tag: noindex
Exemple côté serveur Apache (.htaccess) pour désindexer tous les PDF :
<FilesMatch « \.pdf$ »>
Header set X-Robots-Tag « noindex, follow »
</FilesMatch>
C’est le différenciateur technique : la balise meta gère le HTML, le X-Robots-Tag gère tout le reste.
3. Depuis votre CMS (WordPress : Yoast, Rank Math, SEOPress)
Pas besoin de toucher au code. Avec une extension SEO :
- Au cas par cas : dans l’éditeur de la page → réglages SEO avancés → désactivez « Autoriser les moteurs de recherche à afficher cette page… » (Yoast / SEOPress) ou cochez « No Index » (Rank Math).
- De manière globale : dans les réglages de l’extension, vous pouvez désindexer en masse un type de contenu, une taxonomie (étiquettes) ou des archives (auteur, date).
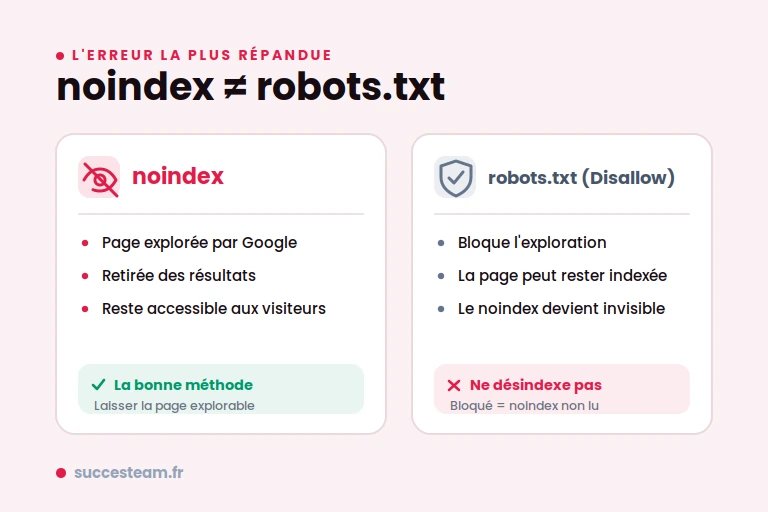
L’erreur classique : noindex et robots.txt ne font PAS la même chose
C’est l’erreur la plus répandue y compris chez des concurrents bien classés. On ne met pas une page en noindex via le robots.txt. Le robots.txt avec une directive Disallow bloque l’exploration (le crawl) d’une URL. Or :
- Une URL bloquée au crawl peut quand même apparaître dans Google (sans description), si d’autres sites pointent vers elle.
- Pire : si vous bloquez la page au crawl, Googlebot ne peut plus lire votre balise noindex.
Résultat : votre consigne de désindexation devient invisible, et la page reste indexée.
Google est formel : la règle noindex ne se déclare pas dans le robots.txt. La bonne marche à suivre pour désindexer : laissez la page explorable (pas de Disallow), et posez le noindex (meta ou X-Robots-Tag). Une fois la page sortie de l’index, vous pourrez éventuellement la bloquer au crawl.
noindex = « tu peux venir voir, mais ne l’affiche pas ». Disallow = « n’entre même pas ». Deux choses différentes.

Noindex, nofollow, canonical, disallow : quelle directive choisir ?
Le bon réflexe dépend de votre objectif. Voici un tableau de décision clair :
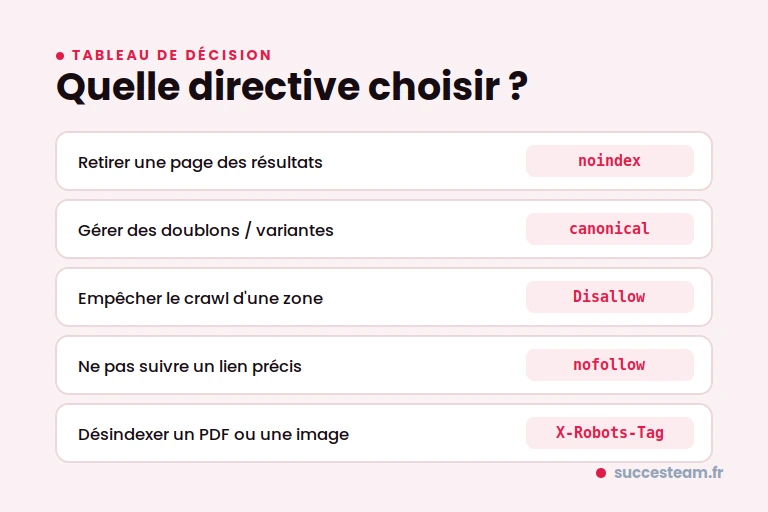
| Votre objectif | La bonne directive | À ne pas utiliser |
|---|---|---|
| Retirer une page des résultats (mais la garder accessible) | noindex (meta ou X-Robots-Tag) | Disallow seul |
| Gérer des doublons / variantes d’une même page | canonical vers la page principale | noindex |
| Empêcher le crawl d’une zone (ressources, back-office) | Disallow (robots.txt) | noindex (le robot ne le verra pas) |
| Ne pas transmettre de confiance via un lien précis | nofollow sur le lien | noindex |
| Désindexer un PDF ou une image | X-Robots-Tag | balise meta (impossible sur un fichier) |
En cas de duplicate content, le réflexe par défaut est donc la balise canonical, pas le noindex. Retenez cette nuance : elle vous évitera bien des erreurs.
Comment vérifier et désindexer une page déjà indexée ?
Pour vérifier l’état d’indexation :
- Google Search Console → rapport Indexation des pages. Les pages désindexées apparaissent sous « Exclue par la balise noindex ». L’outil Inspection de l’URL vous dit précisément si une URL est indexable, et pourquoi.
- La commande site: : tapez site:votredomaine.fr dans Google pour voir, approximativement, ce qui est indexé.
- Un crawler SEO (Ahrefs Site Audit, Screaming Frog…) pour repérer en masse les balises noindex mal placées. C’est typiquement ce que détecte le Site Audit d’Ahrefs : pages bloquées par robots.txt, balises noindex involontaires, erreurs d’exploration.
Pour désindexer une page déjà dans Google :
- Posez la balise noindex (et laissez la page explorable pas de Disallow).
- Attendez le repassage de Googlebot (quelques jours à quelques semaines).
- Pour accélérer, utilisez l’outil de suppression d’URL de la Search Console (effet rapide mais temporaire la balise noindex assure le retrait durable).
- Surveillez l’évolution dans la Search Console, et suivez vos positions avec un outil SEO comme Ranxplorer pour vous assurer que vous n’avez désindexé que ce qu’il fallait.
Et non : le noindex ne supprime pas la page. Il la rend invisible dans les résultats. Pour la supprimer réellement, il faut la supprimer (et gérer une redirection si besoin).
Noindex à l’ère de l’IA et du GEO (2026)
Voici l’angle que les guides classiques ignorent. Avec la montée des réponses génératives (AI Overviews, ChatGPT, Perplexity…), une question revient : « si je mets une page en noindex, est-ce que je l’empêche d’être utilisée par les IA ? »
La réponse courte : non, pas directement. Le noindex pilote l’indexation pour la recherche (les SERP). Il ne contrôle pas, à lui seul, le fait qu’un modèle d’IA explore, mémorise ou cite votre contenu. Ces usages se gèrent via des mécanismes distincts, principalement dans le robots.txt, en ciblant les robots concernés par exemple GPTBot (OpenAI) ou Google-Extended (qui régit l’usage de votre contenu par les modèles génératifs de Google).
Concrètement, pour une stratégie 2026 maîtrisée, raisonnez sur deux niveaux :
- Visibilité Search → balise noindex / X-Robots-Tag (ce guide).
- Visibilité & usage par les IA (GEO/AEO) → directives dédiées aux robots d’IA dans le robots.txt.
Mélanger les deux est une source d’erreurs fréquente. Une page peut très bien être indexée pour Google Searchetexclue de l’entraînement des IA, ou l’inverse. C’est exactement le type d’arbitrage fin sur lequel une agence SEO vous fait gagner du temps (et évite les bourdes coûteuses).
Ce qu’il faut retenir
Le noindex est un excellent outil pour garder la main sur ce que Google affiche de votre site : on l’utilise pour écarter les pages sans valeur, protéger les pages fonctionnelles et préserver son budget de crawl. Les clés : ne pas le confondre avec le robots.txt (laissez la page explorable !), préférer la balise canonical pour le duplicate content, et penser le X-Robots-Tag pour tout ce qui n’est pas du HTML. En 2026, gardez en tête que noindex et visibilité dans les IA sont deux sujets distincts.
Une indexation à auditer ou des pages à nettoyer ?
Pour aller plus loin et maîtriser les termes et définitions importantes du SEO, consultez notre glossaires du référencement naturel