Crawl SEO : le guide complet 2026 pour faire explorer (et indexer) tout votre site
Vous publiez du contenu de qualité, vos pages sont bien rédigées, votre maillage interne tient debout… et pourtant, Google semble ignorer une bonne partie de votre site. Des pages stratégiques ne remontent jamais dans les résultats, certaines mises à jour mettent des semaines à être prises en compte, et vous voyez dans Google Search Console des dizaines d’URL « découvertes mais non indexées ».
Le coupable est presque toujours le même : un problème de crawl. Le crawl SEO, c’est l’étape invisible et fondatrice du référencement naturel. Sans crawl, pas d’indexation. Sans indexation, pas de positionnement. Et en 2026, avec l’explosion des bots d’intelligence artificielle (GPTBot, Google-Extended, PerplexityBot…) qui viennent s’ajouter aux robots classiques, comprendre qui explore votre site, comment, et pourquoi est devenu une compétence stratégique.

Selon les données Cloudflare publiées en 2025, le trafic combiné des bots de recherche et d’IA a progressé de 18 % en un an, avec GPTBot enregistrant une hausse spectaculaire de 305 %. Ignorer cette nouvelle réalité, c’est laisser de l’argent sur la table et potentiellement saboter votre visibilité dans les AI Overviews et les moteurs génératifs.
Dans ce guide rédigé après 5 ans d’audits techniques sur des sites de toutes tailles (de la TPE à l’e-commerce à 100 000 URL), je vais vous partager :
- Ce qu’est vraiment le crawl et comment fonctionnent les robots en 2026
- Les 9 bots à connaître absolument (Googlebot, GPTBot, Google-Extended…) et lesquels autoriser
- Comment fonctionne le budget de crawl et qui devrait s’en préoccuper
- Une méthode d’audit en 6 étapes pour identifier vos blocages de crawl
- Un cas client concret : +47 % de pages indexées en 90 jours
- Les 7 erreurs qui plombent le crawl de 80 % des sites
- Une checklist actionnable à dérouler dès aujourd’hui
Accrochez-vous : à la fin de ce guide, vous saurez exactement pourquoi certaines de vos pages stagnent dans les limbes de Google et comment les en sortir.
Qu’est-ce que le crawl SEO ?
Le crawl SEO (ou crawling, ou exploration) désigne le processus par lequel les robots des moteurs de recherche parcourent automatiquement les pages d’un site web pour en analyser le contenu, suivre les liens, et collecter les informations nécessaires à leur indexation.
Concrètement, ces robots appelés spiders, crawlers ou bots fonctionnent comme un visiteur ultra-rapide :
- Ils arrivent sur une URL connue (depuis un sitemap, un backlink, ou un précédent crawl)
- Ils téléchargent le code HTML de la page
- Ils en extraient le contenu et tous les liens
- Ils ajoutent ces nouveaux liens à leur file d’exploration
- Ils transmettent les données au système d’indexation
Sans cette étape, votre page n’existe pas pour Google. Vous pouvez avoir le contenu le plus brillant du web, s’il n’est pas exploré, il n’a aucune chance d’apparaître dans les SERP.
La trilogie SEO : Crawl → Rendu → Indexation
C’est une distinction cruciale que beaucoup confondent. Trois étapes différentes se succèdent :
| Étape | Ce qui se passe | Outil principal |
|---|---|---|
| Crawl (exploration) | Le robot télécharge l’URL et ses ressources | Googlebot |
| Rendu (rendering) | Le robot interprète le code (HTML, CSS, JS) et « voit » la page | Web Rendering Service |
| Indexation | Google décide d’ajouter ou non la page à son index | Système d’indexation de Google. |
Une page peut être crawlée sans être indexée. C’est l’erreur la plus fréquente en audit : on voit dans Search Console une page « explorée, actuellement non indexée », et on cherche un problème de crawl alors que c’est un problème de qualité ou de pertinence.
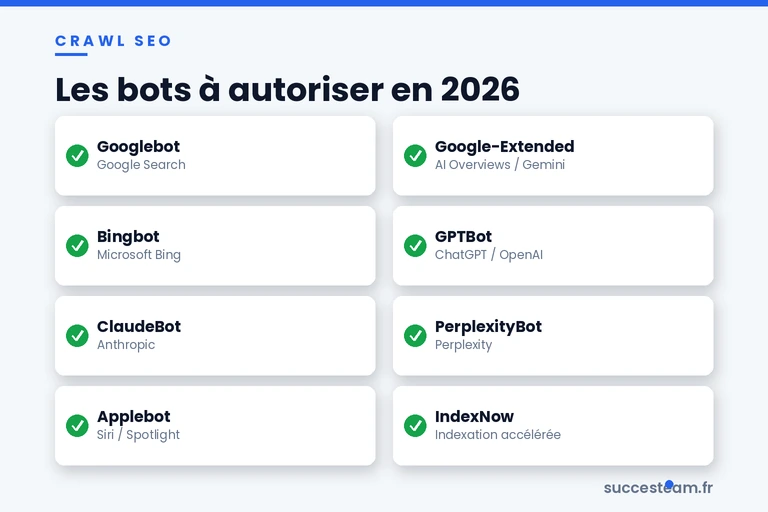
Les 9 bots à connaître absolument en 2026
Voici l’angle que peu de guides traitent en profondeur. En 2026, votre site ne reçoit plus seulement la visite de Googlebot. Voici la liste exhaustive des principaux robots qui explorent (probablement) votre site en ce moment même.
Les robots des moteurs de recherche classiques
| Bot | Moteur | User-agent | À autoriser ? |
|---|---|---|---|
| Googlebot Smartphone | Googlebot/2.1 | ✅ Oui (impératif) | |
| Googlebot Desktop | Googlebot/2.1 | ✅ Oui | |
| Bingbot | Bing/Microsoft | bingbot/2.0 | ✅ Oui |
| Yandexbot | Yandex (Russie) | YandexBot/3.0 | ⚠️ Selon cible |
| Baiduspider | Baidu (Chine) | Baiduspider | ⚠️ Selon cible |
| Applebot | Apple (Siri, Spotlight) | Applebot | ✅ Oui |
Les nouveaux bots IA (la grande nouveauté 2024-2026)
| Bot | Société | À quoi il sert | Recommandation |
|---|---|---|---|
| GPTBot | OpenAI | Entraînement de ChatGPT, citations dans ChatGPT Search | ✅ Autoriser pour le GEO |
| Google-Extended | Alimentation des AI Overviews et Gemini | ✅ Impératif pour AI Overviews | |
| PerplexityBot | Perplexity | Citations dans les réponses Perplexity | ✅ Autoriser |
| ClaudeBot | Anthropic | Citations dans Claude | ✅ Autoriser |
Le détail technique que personne ne mentionne : la limite des 2 Mo de Googlebot
Information cruciale : Le détail technique que peu de guides ont intégré : la limite de 2 Mo confirmée par Google. En février 2026, Google a clarifié sa documentation crawler : pour l’indexation Search, Googlebot ne récupère que les 2 premiers Mo d’un fichier HTML (et les 64 premiers Mo d’un PDF). Au-delà, il arrête la récupération et ne transmet que la partie déjà téléchargée à l’indexation.
Deux précisions importantes :
Google a précisé qu’il s’agit d’une clarification de documentation, pas d’un changement de comportement : le seuil s’applique aux données non compressées.
Cette limite de 2 Mo concerne Googlebot pour Search. La limite générale de 15 Mo continue de s’appliquer à l’infrastructure de crawl de Google (autres robots : Images, News, Shopping, services IA…).
En pratique, la page HTML médiane pèse environ 30 Ko vous êtes très loin du plafond. Le risque concerne les pages obèses (CSS inline massif, images en base64, gros bundles JavaScript). Mon conseil : vérifiez le poids HTML de vos pages stratégiques (PageSpeed Insights, DevTools) et gardez le contenu important en début de document, jamais au-delà de la barre des 2 Mo.
Comment fonctionne Googlebot en 2026
Googlebot est passé en mobile-first indexing depuis 2019. En 2026, la quasi-totalité du crawl s’effectue désormais via l’agent mobile, Googlebot Desktop ne servant plus que pour des vérifications croisées.

Le parcours type d’un crawl
- Découverte : Googlebot récupère une URL depuis son catalogue (sitemap, backlinks, crawls précédents)
- Vérification robots.txt : il vérifie d’abord si l’URL est autorisée à être crawlée
- Téléchargement : il télécharge le contenu HTML brut
- Extraction : il extrait les balises meta, le contenu textuel, les liens, les images
- Rendu (si nécessaire) : pour les pages JavaScript-heavy, il déclenche un rendu via le Web Rendering Service (souvent avec un délai de plusieurs jours)
- Décision d’indexation : Google évalue la qualité, l’unicité et la pertinence avant d’ajouter la page à son index
Le cas particulier du JavaScript : un piège que personne n’explique
Si votre site utilise un framework JavaScript (React, Vue.js, Angular) avec du rendu côté client (CSR), Googlebot va :
- Récupérer le HTML brut (souvent quasi vide)
- Mettre la page dans une file d’attente pour le rendu
- Effectuer le rendu plus tard (parfois 1 à 9 jours)
- Seulement à ce moment-là, indexer le contenu réel
Conséquence : vos pages mettent beaucoup plus de temps à apparaître dans les SERP, et certaines ne sont jamais correctement crawlées.
Solution recommandée : SSR (Server-Side Rendering) ou SSG (Static Site Generation) avec des outils comme Next.js, Nuxt.js ou des solutions de pré-rendu.
Le budget de crawl : pour qui et pourquoi ?
Le budget de crawl désigne le nombre de pages que Googlebot peut et veut explorer sur votre site sur une période donnée. C’est l’un des concepts SEO les plus mal compris.
Les deux composantes du budget
Selon la documentation officielle de Google (mise à jour décembre 2025), le budget de crawl se compose de :
- La limite de capacité d’exploration (crawl rate limit) : la vitesse à laquelle Google peut crawler sans surcharger votre serveur
- La demande d’exploration (crawl demand) : l’intérêt que Google porte à votre contenu
Pour augmenter votre budget, vous n’avez que deux leviers :
- Améliorer la qualité du contenu (Google alloue plus de ressources aux contenus à forte valeur)
- Améliorer la capacité serveur (vitesse, stabilité, CDN)
Pour qui le budget de crawl est-il critique ?
Soyons honnêtes : pour 80 % des sites, le budget de crawl n’est pas un problème majeur. Si vous avez moins de 10 000 URL et que votre site se charge correctement, Google explorera tout ce qu’il faut.
Le budget de crawl devient critique pour :
- Les catalogues e-commerce de plus de 10 000 produits
- Les portails d’actualités avec des dizaines d’articles publiés par jour
- Les marketplaces et plateformes générant des URL dynamiques
- Les sites avec navigation à facettes (filtres qui créent des URL combinatoires)
- Les forums et plateformes communautaires
- Les sites internationaux avec plusieurs versions linguistiques
Si vous êtes dans une de ces catégories, le budget de crawl mérite une vigilance particulière.
Les voleurs de budget les plus fréquents
Voici ce qui gaspille (vraiment) votre budget de crawl :
| Problème | Impact | Solution |
|---|---|---|
| Erreurs 404 récurrentes | Élevé | Corriger ou rediriger en 301 |
| Chaînes de redirections (301 → 301 → 301) | Élevé | Rediriger directement vers la destination finale |
| URL avec paramètres infinis (filtres, tris) | Très élevé | Robots.txt ou canonicals |
| Pages dupliquées (variantes produits) | Élevé | Canonical tags |
| Pagination excessive (page 1 à 500) | Moyen | rel= »next/prev » ou paginer intelligemment |
| Pages de recherche interne indexées | Élevé | Bloquer en robots.txt |
| Soft 404 (pages vides qui renvoient 200) | Moyen à élevé | Renvoyer un vrai 404 ou enrichir le contenu |
Méthode pas-à-pas : auditer le crawl de votre site en 6 étapes
Voici la procédure que j’utilise sur tous mes audits clients. Comptez 2 à 4 heures pour un site de taille moyenne.
Étape 1 : Vérifier ce que Google voit avec la commande site:
Tapez dans Google :
site:votredomaine.com Vous obtenez le nombre approximatif de pages que Google a indexées sur votre site. Comparez à votre nombre réel de pages publiées :
- Écart faible (-10 %) : tout va bien
- Écart moyen (-30 %) : problème probable, lancez un audit
- Écart majeur (-50 % ou plus) : alerte rouge, problème de crawl ou de qualité
Étape 2 : Auditer la couverture d’index dans Google Search Console
Dans Search Console > Indexation > Pages, vous trouverez les statuts suivants :
- Pages indexées : ce que Google a accepté
- Pages non indexées : ce qui pose problème
Concentrez-vous sur les motifs les plus fréquents :
- Découverte, actuellement non indexée → souvent un problème de qualité
- Explorée, actuellement non indexée → Google a vu la page mais ne la juge pas digne
- Page avec redirection → vérifiez la chaîne de redirection
- Bloquée par robots.txt → vérifiez que c’est intentionnel
- Exclue par balise « noindex » → idem
- Erreur du serveur (5xx) → urgence technique
- Introuvable (404) → corriger ou rediriger
Étape 3 : Analyser les statistiques de crawl
Dans Search Console > Paramètres > Statistiques de crawl, vous voyez :
- Le nombre total de requêtes de crawl (variation J-30, J-90)
- Le temps de réponse moyen du serveur
- La disponibilité de l’hôte
- Le détail par type de fichier (HTML, images, CSS…)
Signaux d’alerte :
- Chute brutale du nombre de crawls → problème serveur, robots.txt ou pénalité
- Temps de réponse > 600 ms → Google va réduire son taux de crawl
- Pic d’erreurs 5xx → urgence technique
Étape 4 : Lancer un crawl complet du site
Outils recommandés :
- Screaming Frog (jusqu’à 500 URL gratuit, illimité avec licence)
- Sitebulb (excellent pour les visualisations)
- Oncrawl ou Botify (pour les très gros sites)
- Ahrefs Site Audit ou Semrush Site Audit (intégré aux outils SEO)
Ce que vous cherchez :
- Pages 404 internes (liens cassés)
- Chaînes de redirections > 2 sauts
- Pages orphelines (sans aucun lien interne)
- Profondeur excessive (> 4 clics depuis l’accueil)
- Contenus dupliqués (titles, descriptions, body)
Étape 5 : Analyser les logs serveur (l’arme ultime)
C’est l’étape que 90 % des sites négligent, et c’est pourtant la plus puissante. Les logs serveur vous montrent exactement ce que Googlebot et les autres bots font sur votre site.
Outils :
- Screaming Frog Log File Analyser (le plus accessible)
- Oncrawl Log Analyzer
- Splunk ou ELK Stack (pour les très gros sites)
Ce que vous découvrirez :
- Quelles URL Googlebot crawle vraiment (vs lesquelles il ignore)
- À quelle fréquence
- Quel temps de réponse il rencontre
- Quels codes HTTP il reçoit
- Si des bots IA explorent votre site et lesquels
💡 Le détail qui change tout : sur un audit récent, j’ai découvert que Googlebot consacrait 60 % de son budget de crawl à des URL de filtres de recherche interne sur un site e-commerce. Après blocage en robots.txt, le nombre de pages produits crawlées a doublé en 3 semaines.
Étape 6 : Vérifier le fichier robots.txt et le sitemap XML
Robots.txt :
- Accessible à votredomaine.com/robots.txt
- Ne bloque pas par erreur des pages importantes
- Référence le sitemap
- Accessible à votredomaine.com/sitemap.xml
- Contient uniquement des URL canoniques et indexables
- Pas d’URL en noindex, 404 ou redirigées
- Mis à jour automatiquement
- Soumis dans Google Search Console
Étude de cas : +47 % de pages indexées en 90 jours
Pour illustrer l’impact concret d’un travail sur le crawl, voici un cas client réel (anonymisé).
Contexte : Site e-commerce de mobilier design, 28 000 fiches produits, 4 200 articles de blog, hébergement OVH.

Diagnostic initial (mars 2025) :
- 11 500 pages indexées sur 32 200 (seulement 36 %)
- 14 800 URL en « Découverte, actuellement non indexée »
- Temps de réponse serveur moyen : 1,2 seconde
- Robots.txt sans optimisation
- Sitemap contenant 18 000 URL dont 6 000 en redirection
Actions mises en place :
- Optimisation serveur : passage en CDN Cloudflare + mise en cache → temps de réponse ramené à 340 ms
- Refonte du robots.txt : blocage des URL de filtres, de tri, de recherche interne et de panier
- Sitemap nettoyé : uniquement les URL canoniques actives, soit 24 800 URL
- Correction de 3 200 chaînes de redirection (rediriger A → C plutôt que A → B → C)
- Suppression des paramètres URL inutiles via la console Google
- Soumission au protocole IndexNow pour accélérer la prise en compte des nouveautés
- Autorisation explicite des bots IA (GPTBot, Google-Extended, PerplexityBot) dans le robots.txt
Résultats à 90 jours :
| Indicateur | Avant | Après | Évolution |
|---|---|---|---|
| Pages indexées | 11 500 | 16 900 | +47 % |
| Temps de réponse moyen | 1,2 s | 340 ms | -72 % |
| Requêtes Googlebot/jour | 18 000 | 41 000 | +128 % |
| Trafic organique mensuel | 142 000 | 197 000 | +39 % |
| Apparitions dans AI Overviews | 0 | 14 | +∞ |
💡La leçon : le crawl est probablement le levier SEO avec le meilleur ratio effort/résultat sur les sites de taille moyenne à grande. 2 semaines de travail technique peuvent débloquer des mois de croissance.
Crawl SEO et IA générative : les nouvelles règles 2026
Voici la section que vous ne trouverez complète nulle part ailleurs. La montée des moteurs génératifs transforme en profondeur ce qu’on attend du crawl.
Pourquoi le crawl conditionne désormais votre visibilité IA
Si Googlebot ne peut pas explorer correctement votre contenu, Google-Extended (le robot dédié aux AI Overviews) ne le pourra pas non plus. Sans crawl propre, pas de citation dans les AI Overviews, ChatGPT Search, Perplexity ou Gemini.
L’éligibilité aux interfaces IA repose sur trois piliers :
- Accessibilité technique : le bot peut accéder à votre contenu
- Lisibilité sémantique : le contenu est structuré pour être extractible
- Crédibilité (E-E-A-T) : votre site fait autorité sur le sujet
Le crawl est le prérequis absolu des deux suivants.
Comment configurer son robots.txt pour les bots IA
Voici un modèle de robots.txt optimisé en 2026 pour un site classique souhaitant maximiser sa visibilité IA :
# Bots Google
User-agent: Googlebot
Allow: /
User-agent: Google-Extended
Allow: /
# Bots Microsoft
User-agent: Bingbot
Allow: /
# Bots IA externes
User-agent: GPTBot
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: PerplexityBot
Allow: /
# Apple
User-agent: Applebot
Allow: /
# Règles globales
User-agent: *
Disallow: /panier/
Disallow: /admin/
Disallow: /*?s=
Disallow: /*?filter=
Sitemap: https://votredomaine.com/sitemap.xml
Quand bloquer les bots IA ?
Vous pouvez bloquer les bots IA si :
- Vous craignez que vos contenus soient utilisés pour entraîner des modèles concurrents
- Votre business model repose sur du contenu premium payant
- Vous avez des préoccupations légales (données sensibles, contenus exclusifs)
Vous devez les autoriser si :
- Vous voulez apparaître dans les AI Overviews de Google
- Vous voulez être cité par ChatGPT, Perplexity ou Claude
- Votre stratégie inclut le GEO (Generative Engine Optimization)
Pour 90 % des entreprises, autoriser les bots IA est la bonne stratégie en 2026. La visibilité dans les réponses IA devient un canal d’acquisition majeur.
Les 7 erreurs de crawl qui plombent 80 % des sites
Au fil de mes audits, voici les erreurs qui reviennent systématiquement.
Erreur 1 : Bloquer Googlebot par accident dans robots.txt
L’erreur classique du développeur pressé. Une ligne Disallow: / oubliée d’une phase de pré-production peut anéantir des mois de SEO.
Vérification : allez à votredomaine.com/robots.txt et lisez le fichier. Si vous voyez User-agent: * Disallow: /, paniquez (calmement).
Erreur 2 : Sitemap XML contenant des URL en noindex ou 404
Votre sitemap est censé être un plan de route propre pour Google, pas un déversoir. Un sitemap pollué d’URL mortes signale à Google que vous ne maîtrisez pas votre site.
Solution : régénérez votre sitemap avec un plugin SEO sérieux (Yoast, Rank Math, AIOSEO) qui exclut automatiquement les URL noindex.
Erreur 3 : Architecture trop profonde
La règle d’or : toute page stratégique doit être accessible en 3 clics maximum depuis la page d’accueil. Au-delà, Google explore moins fréquemment et accorde moins de poids.
Solution : travaillez votre maillage interne et vos pages catégorie pour aplatir l’arborescence.
Erreur 4 : Trop de paramètres URL non gérés
Sur un site e-commerce typique, une fiche produit peut générer des dizaines de variantes d’URL via les filtres, tris, ID de session, etc.
Solution : utilisez les balises canonical, le robots.txt et le rapport « Paramètres d’URL » de Google Search Console pour rationaliser.
Erreur 5 : Pages orphelines invisibles
Une page sans aucun lien interne pointant vers elle est invisible pour Googlebot, sauf si elle apparaît dans le sitemap (et encore, c’est aléatoire).
Solution : auditez avec Screaming Frog (rapport « Orphan Pages ») et tissez systématiquement du maillage interne.
Erreur 6 : Temps de réponse serveur élevé
Au-delà de 600 ms de temps de réponse moyen, Google réduit volontairement son taux de crawl pour ne pas surcharger votre serveur. Implication directe : moins de pages crawlées, moins d’indexation, moins de trafic.
Solution : CDN, mise en cache, base de données optimisée, hébergement adapté.
Erreur 7 : Ne pas surveiller son crawl
Sans suivi régulier des statistiques de crawl, vous ne savez pas quand un problème survient. J’ai vu des sites perdre 40 % de leur trafic en 3 semaines à cause d’un robots.txt mal configuré, simplement parce que personne ne surveillait Search Console.
Solution : consultez Google Search Console au minimum 1 fois par semaine.
Checklist : votre site est-il optimisé pour le crawl ?
Avant de fermer cet article, passez ce contrôle en revue. Cochez ce qui est en place :
Configuration de base
- Le fichier robots.txt est accessible et correctement configuré
- Un sitemap XML est généré automatiquement et soumis à Google Search Console
- Aucune balise noindex ne traîne sur des pages stratégiques
- Le site est en HTTPS avec un certificat SSL valide
Performance technique
- Le temps de réponse serveur est inférieur à 600 ms
- Les pages pèsent moins de 1,5 Mo (limite Googlebot : 2 Mo)
- Un CDN est en place pour les sites multi-régionaux
- Les images sont compressées (WebP, AVIF)
Architecture
- Toute page stratégique est à 3 clics maximum de l’accueil
- Le maillage interne est cohérent (pas de pages orphelines)
- Les URL sont propres, courtes et descriptives
- Pas de chaînes de redirections > 2 sauts
Qualité du crawl
- Les erreurs 404 sont surveillées et corrigées régulièrement
- Les paramètres URL inutiles sont bloqués ou canonicalisés
- Les pages de recherche interne ne sont pas indexées
- Le sitemap ne contient que des URL canoniques actives
Optimisation IA / GEO
- Google-Extended est autorisé dans le robots.txt
- GPTBot, PerplexityBot, ClaudeBot sont autorisés (ou bloqués en connaissance de cause)
- IndexNow est implémenté pour accélérer la prise en compte des nouveautés
- Données structurées Schema.org déployées (Article, FAQPage, HowTo…)
Monitoring
- Statistiques de crawl consultées au moins 1 fois/semaine
- Audit Screaming Frog mensuel
- Analyse de logs trimestrielle (pour les sites > 10 000 URL)
Si vous cochez 18/22 cases, vous êtes au-dessus de 90 % des sites français. 22/22 = vous avez une infrastructure SEO de classe entreprise.
Ce qu’il faut retenir
Le crawl SEO n’est pas un sujet technique ennuyeux réservé aux développeurs : c’est la fondation invisible de toute stratégie de référencement réussie. Sans crawl propre, vos contenus brillants restent dans l’ombre, vos optimisations on-page n’ont aucun impact, et votre stratégie GEO/IA est mort-née. Récapitulons les points essentiels :
- Le crawl précède l’indexation et le positionnement c’est l’étape n°1
- Connaissez vos bots : Googlebot + Bingbot + bots IA (GPTBot, Google-Extended, PerplexityBot, ClaudeBot)
- Surveillez votre budget de crawl uniquement si vous avez > 10 000 URL
- Auditez régulièrement avec Search Console, Screaming Frog et l’analyse de logs
- Optimisez la performance serveur : c’est le levier n°1 d’amélioration du crawl
- Configurez votre robots.txt pour le GEO : autorisez les bots IA pour exister dans les réponses synthétisées
- Une page orpheline est une page invisible : maillage interne obligatoire
Le SEO a toujours été un métier d’invisible : ce qui se passe en coulisses détermine ce qui apparaît en façade. Le crawl est précisément cette coulisse essentielle. Maîtrisez-le, et vous aurez creusé un fossé difficile à combler face à vos concurrents.
Besoin d’un audit complet du crawl de votre site ? Succesteam réalise des audits techniques approfondis pour identifier vos blocages d’exploration et débloquer votre potentiel SEO.Demandez votre audit personnalisé
Pour aller plus loin, consultez notre glossaires du référencement naturel :
https://succesteam.fr/definition/